1965 results
tagged
nomarkdown x
-
Errata Security: Extracting the SuperFish certificate [la clé privée et son mot de passe, surtout]
Via https://twitter.com/ErrataRob/status/56841408282039910419/02/2015 15:49:11 - permalink -
Un PoC est même disponible : https://canibesuperphished.com/
Via https://twitter.com/supersat/status/568372787196243968
Quelle surprise, on ne s'y attendait pas du tout ! :))))- http://blog.erratasec.com/2015/02/extracting-superfish-certificate.html
-
RFC 7465 - Prohibiting RC4 Cipher Suites
\o/19/02/2015 11:55:53 - permalink -
Au moins le mouv' est amorcé, reste plus qu'à attendre la mise en œuvre puis à déprécier tous les autres algos qui ont fait leur temps.- http://www.rfc-editor.org/rfc/rfc7465.txt
-
Le constructeur de PC ripou #Lenovo livre ses poubelles avec un #adware pré-installé, quoi vous affiche des pubs dans vos sessions Web.
« Le constructeur de PC ripou #Lenovo livre ses poubelles avec un #adware pré-installé, quoi vous affiche des pubs dans vos sessions Web. Bien pire, le navigateur est pré-configuré avec une Autorité de Certification [NDLR : X509] pirate (#SuperFish), ce qui permet de casser [NDLR : contourner plutôt : une des 2 parties de la communication est vérolée] TLS (attaque de l’Homme du Milieu) et donc de mettre les pubs même sur les sessions HTTPS. Seule solution : reformater tout PC acheté et y mettre un système d’exploitation de confiance (en attendant que les entreprises capitalistes mettent le malware dans le BIOS). » +1 :'(19/02/2015 10:48:54 - permalink -
« It looks like Lenovo has been installing adware onto new consumer computers from the company that activates when taken out of the box for the first time.
The adware, named Superfish, is reportedly installed on a number of Lenovo’s consumer laptops out of the box. The software injects third-party ads on Google searches and websites without the user’s permission.
[...]
A Lenovo community administrator, Mark Hopkins, wrote in late January that the software would be temporarily removed from current systems after irate users complained of popups and other unwanted behavior:
[...]
Other users are reporting that the adware actually installs its own self-signed certificate authority [NDLR : self-signed ? normal pour un certificat d'AC] which effectively allows the software to snoop on secure connections, like banking websites as pictured in action below.
This is a malicious technique commonly known as a man-in-the middle attack, where the certificate allows the software to decrypt secure requests [...] If this is true — we’ve only seen screenshots so far — Superfish could be far more dangerous than just inserting advertising.
[...]
Reports of Superfish being pre-loaded on Lenovo computers have appeared on forums as early as mid-2014.
[...]
Update: Mozilla Firefox does not appear to be affected by the SSL man-in-the-middle issue, because it maintains its own certificate store. »
« A pretty shocking thing came to light this evening – Lenovo is installing adware that uses a “man-in-the-middle” attack to break secure connections on affected laptops in order to access sensitive data and inject advertising. As if that wasn’t bad enough they installed a weak certificate into the system in a way that means affected users cannot trust any secure connections they make – TO ANY SITE.
However Superfish’s software has quite a reputation. It is a notorious piece of “adware”, malicious advertising software. A quick search on Google reveals numerous links for pages containing everything from software to remove Superfish to consumers complaining about the presence of this malicious advertising tool.
Superfish Features:
Hijacks legitimate connections.
Monitors user activity.
Collects personal information and uploads it to it’s servers
Injects advertising in legitimate pages.
Displays popups with advertising software
Uses man-in-the-middle attack techniques to crack open secure connections.
Presents users with its own fake certificate instead of the legitimate site’s certificate.
[...]
This presents a security nightmare for affected consumers.
Superfish replaces legitimate site certificates with its own in order to compromise the connections so it can install its adverts. This means that anyone affected by this adware cannot trust any secure connections they make.
Users will not be notified if the legitimate site’s certificate has been tampered with, has expired or is bogus. In fact they now have to rely on Superfish to perform that check for them. Which it does not appear to do.
Because Superfish uses the same certificate for every site it would be easy for another hostile actor to leverage this and further compromise the user’s connections.
The user has to trust that this software which has compromised their secure connections is not tampering with the content, or stealing sensitive data such as usernames and passwords.
If this software or any of its control infrastructure is compromised, an attacker would have complete and unrestricted access to affected customers banking sites, personal data and private messages. »
ÉDIT du 19/02/2014 à 13h55 :
« Clubic explique cependant qu'une manipulation permet au départ d'éviter de l'installer.
«L'utilisateur a la possibilité de refuser l'installation de ce programme en décochant une petite case au moment où il allume pour la première fois son nouveau PC, mais évidemment, peu font attention à ce genre de détails.» [NDLR : ok, c'est cool mais la source / méthodologie pour arriver à cette conclusion n'est pas indiquée.]
[...]
Et, si vous n'avez pu l'éviter, «il est très simple de désinstaller Superfish. Voici d'ailleurs une vidéo qui vous explique comment procéder»:
[NDLR : apparemment, ce n'est pas aussi simple : « Readers should be aware that even after uninstalling the Superfish adware from their machines, the Superfish root certificate will remain. » ;) ]
[...]
Rien qu'en 2014, Lenovo a vendu plus de 59 millions de PC, faisant de lui le numéro un du marché, selon Gartner. »
« It installs a self-signed root HTTPS certificate that can intercept encrypted traffic for every website a user visits. When a user visits an HTTPS site, the site certificate is signed and controlled by Superfish and falsely represents itself as the official website certificate.
[...]
Even worse, the private encryption key accompanying the Superfish-signed Transport Layer Security certificate appears to be the same for every Lenovo machine. Attackers may be able to use the key to certify imposter HTTPS websites that masquerade as Bank of America, Google, or any other secure destination on the Internet. Under such a scenario, PCs that have the Superfish root certificate installed will fail to flag the sites as forgeries—a failure that completely undermines the reason HTTPS protections exist in the first place.
[...]
Palmer [NDLR : un chercheur en sécurité info semble-t-il] was later able to confirm that the private key for the Superfish certificate installed on his Yoga 2 contained the same private key as a Superfish certificate installed on a different person's Lenovo PC. That means there's a good chance attackers could use the certificate to create fake HTTPS websites that wouldn't be detected by vulnerable Lenovo machines. »
Ok donc un faux certificat X509 est généré à la volée sur le PC infecté pour chaque site web consulté. Il ne s'agit pas juste de quelques certificats pré-générés valides seulement pour quelques sites web bien connus (exemple : top X Alexa) !)
FIN DE L'ÉDIT.
ÉDIT du 19/02/2015 à 15h55 : Et vlaaaaam la clé privée et son mot de passe : http://shaarli.guiguishow.info/?TBUR6w FIN DE L'ÉDIT
En résumé : un assembleur PC ripou, un adware et la magie de X509. COMBO !- http://seenthis.net/messages/343659
-
Vie privée : et le DNS alors ?
« Si le serveur autorité de youporn.com était dans le réseau qui allait servir la page www.youporn.com, vu que 10ms après avoir demandé « qui est www.youporn.com ? » à X.X.X.53, X.X.X.80 verrait arriver une requête HTTP « est-ce que je peux avoir /watch/9912017/sexe-alcool-et-vie-privee/ ? ». Et donc globalement, à part moi-même et YouPorn, personne ne serait au courant de mon penchant pour les chatons dans les tuyaux. »19/02/2015 10:30:48 - permalink -
Non ! au moins un des serveurs DNS qui fait autorité sur com. serait aussi informé puisque le récursif lui demandera « www.youporn.com. A ? » et qu'il répondra : « youporn.com. 172800 IN NS pdns3.ultradns.org. [...] ». S'il ne le fait pas, c'est qu'il a déjà la délégation en cache et donc... qu'il a déjà demandé dans le passé.
« Afin de bien voir l’ampleur de la catastrophe, j’ai développé un outil (zone github.com résolue par Dyn, donc Dyn est maintenant au courant que vous avez achetez un cadeau à votre petit·e ami·e sur Amazon pour la Saint-Valentin et que vous savez coder, ce qui vous classe en plus dans le 0.1% des geeks en couple :P) qui analyse les serveurs autorités des 100.000 sites les plus fréquentés au monde (liste fournie par Alexa, alexa.com servie par Amazon, donc en plus on sait maintenant que vous vous intéressez au web).
Après 4h de requétage DNS intensif, le résultat complet est disponible ici, référençant quelques 23 578 serveurs autorités (pour 100.000 sites ! On devrait en avoir quelques 200.000 si tout le monde s’auto-hébergeait !!!).
Le résultat est sans appel :
Fournisseur NS % % cumulés
1. awsdns 25912 9,72% 9,72%
2. cloudflare.com 16808 6,31% 16,03%
3. domaincontrol.com 9626 3,61% 19,64%
4. dnsmadeeasy.com 8786 3,30% 22,94%
5. dynect.net 8234 3,09% 26,03%
6. akamai 7056 2,65% 28,68%
7. ultradns 4921 1,85% 30,52%
8. registrar-servers.com 3293 1,24% 31,76%
9. name-services.com 3079 1,16% 32,92%
10. hichina.com 3041 1,14% 34,06%
Amazon héberge à lui tout seul 10% du top 100k. Le top 10 des fournisseurs représente un tiers du trafic. Le top 50 intercepte la moitié du trafic DNS. Il faut attendre d’avoir intercepté plus de 80% du trafic pour enfin voir des gens s’héberger en propre (StackOverflow, Reddit…).
Si on regarde uniquement le top 10k, les 10 plus gros fournisseurs draînent 43% du trafic, et pire sur le top 1000, les 3 plus gros se taillent la part du lion avec 33% de part de marché…
En bref, il suffit de trouilloter un très petit nombre de prestataires pour pouvoir suivre à la trace une bonne moitié de la planète…
On constate même que les marketeux ont bien compris l’intérêt du tracking par DNS, avec par exemple la présence de l’Observatoire des marques (5 NS du top 10k et 77 NS du top 100k) ou encore MarkMonitor (85 NS du top 10k et 693 NS du top 100k) et qui n’ont pour unique but que de surveiller le DNS pour dresser des stats de fréquentation… »
Pour des infos complémentaire vie privée <-> DNS, voir aussi l'excellent DNS privacy considerations - https://tools.ietf.org/html/draft-ietf-dprive-problem-statement-01- https://blog.imirhil.fr/vie-privee-et-le-dns-alors.html
-
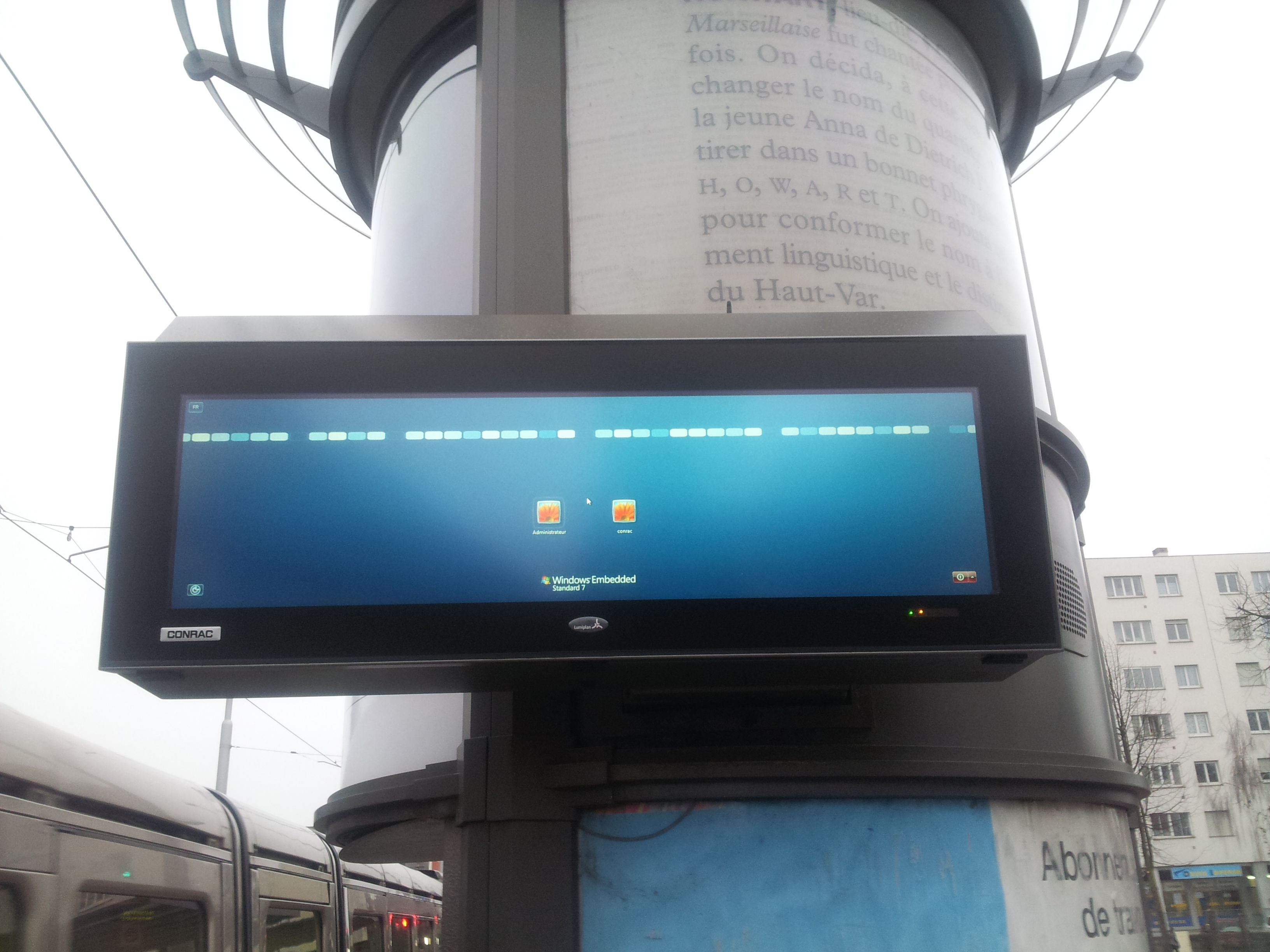
Changement des écrans d'affichage des horaires aux arrêts de tram de la Compagnie des Transports Strasbourgeois et l'enfer winwin
La Compagnie des Transports Strasbourgeois a changé les écrans d'affichage des horaires aux arrêts de tramways : on passe d'écrans à LEDS à des écrans+ordinateur. C'est encore en cours de déploiement (exemple : ligne A, tronçon Illkirch - Rotonde : OK, esplanade : NOK).19/02/2015 02:09:27 - permalink -
D'une part, ces nouveaux écrans sont moins lisibles et probablement plus consommateurs en énergie (LEDs versus écran complet + ordi derrière).
D'autre part, ils fonctionnent sous winwin Embedded ! N'importe quel système d'exploitation libre et gratuit développé en toute transparence par des communautés mondiales (famille GNU/Linux ou BSD) est capable de remplir une mission d'affichage aussi simple mais non, il faut avoir recours au produit propriétaire et payant fourni par une multinationale états-unienne opaque qui pratique l'évasion fiscale ! Il faut absolument utiliser des produits à l'éthique douteuse et jeter l'argent public et celui des usagers (vente de titres de transport) par la fenêtre !
Oui, je suis conscient que ce n'est pas évident car seulement quelques sociétés commerciales fournissent des « panneaux lumineux électroniques destinés à l'affichage d'informations dynamiques » basés sur un système d'exploitation libre GNU/Linux : Data Modul, Eyevis, Conrac,... et que ces sociétés ne sont peut-être pas en capacité de supporter un "gros" projet comme celui de la CTS. Peut-être que le système d'information derrière est codé/intégré par une société commerciale qui dev' sur winwin only... Mauvais prestataires, essayer de changer de prestataires.
Oui, la CTS a eu recours à un prestataire externe dans le cadre d'un appel d'offres public (http://ted.europa.eu/udl?uri=TED:NOTICE:206188-2013:TEXT:FR:HTML&src=0). Néanmoins, la CTS aurait pu définir l'utilisation de logiciels libres par le prestataire comme un critère de choix ou, tout au moins, comme un souhait fort (afin que l'appel d'offres ne soit pas fermé donc potentiellement invalidé). Ce type d'action favoriserait l'intérêt commun, éveillerait l'intérêt de fournisseurs de solutions libres qui se sentent habituellement exclus d'office des appels d'offres publics et inciterait le marché à devenir plus éthique.
Qu'on ne vienne pas me parler de coûts annexes à ceux des licences qui rendrait le logiciel propriétaire et payant plus intéressant : on ne s'adresse pas à des utilisateurs finaux (il ne s'agit pas de postes de travail dans une entreprise, une administration ou une école) donc les coûts de formation sont inexistants. Nous sommes sur un service de base (de l'affichage quoi !) d'un service existant donc le besoin (et donc le coût) en support payant pour migrer et maintenir le système est, au mieux inexistant, au pire strictement égal à l'actuel.
Bon, en même temps, à quoi s'attendre de la part d'une compagnie de transports en commun qui utilise du propriétaire à tous les niveaux (dev' des solutions internes, bornes/distributeurs aux arrêts de tram, bases de données Oracle (en cours de migration vers MS SQL server), serveurs mails, ...) et qui fait de l'open data fermé (https://strasweb.fr/2012/08/18/opendata-cts/) ? Pour moi, cela démontre avant tout un manque de volonté de la CTS plutôt qu'un manque de fournisseurs / marché public aux procédures strictes.
Bon, pour être honnête, la CTS utilise un peu de GNU/Linux pour au moins les sauvegardes et les transmissions. Joie ! C'est comme pour la défense (http://www.nextinpact.com/news/79148-le-contrat-entre-defense-et-microsoft-sera-reconduit-april-scandalisee.htm), il y'a un foutu partenariat avec MS ou quoi ?!
C'est dommage... Ne pas utiliser de solutions éthiques pour résoudre des problématiques aussi simples...
Nous (un groupe informel de 18 personnes) avons exprimé notre mécontentement par mail à la CTS et à Lumiplan (prestataire) hier (18/02) sur la base des arguments présentés ci-dessus (et réciproquement, d'ailleurs). Réponse standard "mail transmis aux personnes concernées". Via des voix en off, nous savons :
- Que le mail est parvenu jusqu'au chef de projet concerné ;
- Que notre mail a produit uniquement un effet minimal (aka "il sera bien vite oublié") mais qu'il a au moins produit de l'effet... À force de gratter et sur un malentendu, on arrivera peut-être un jour à ce que la CTS reconsidère ce choix en faveur de logiciels libres ;
- La CTS a uniquement imposé les fonctionnalités dans le cahier des charges et le système d'exploitation n'est clairement pas un critère décisif ;
En attente d'une éventuelle réponse de la part de la CTS...- http://www.guiguishow.info/wp-content/uploads/2015/02/cts_ecran_tram_hohwart_winwin.jpg
-
Using Look-ahead and Look-behind - Johndescs's mini-recording
grep -P (version récente).18/02/2015 11:04:39 - permalink -
Autre ressource intéressante sur les regex look ahead/behind : http://carijansen.com/2013/03/03/positive-lookahead-grep-for-designers/
Exemple concret :
On a un fichier contenant des lignes de la forme :
« blablablabla blablablabla id=666 blabla
blablablabla blablablabla id=42 blabla »
On veut extraire les ID et les trier par ordre croissant afin de récupérer l'ID le plus élevé (qui n'est donc pas forcément à la dernière ligne du fichier).
Sans ces regex, on ferait : grep -oE "id=[0-9]+" <fichier> | grep -oE "[0-9]+$" | sort -g | tail -n1
Avec une regex look-behind : grep -Po "(?<=id=)[0-9]+" <fichier> | sort -g | tail -n1- http://home.michalon.eu/shaarli/?q1Sjuw
-
Duplicate SSH Keys Everywhere
« Back in December when I revamped the SSH banner and started collecting the fingerprint I noticed an odd behavior. It turns out that a few SSH keys are used a lot more than once. For example, the following SSH fingerprint can be found on more than 250,000 devices!18/02/2015 10:32:02 - permalink -
[...]
It looks like all devices with the fingerprint are Dropbear SSH instances that have been deployed by Telefonica de Espana. It appears that some of their networking equipment comes setup with SSH by default, and the manufacturer decided to re-use the same operating system image across all devices.
The next duplicated fingerprint on the list comes in at around 200,000 devices, followed by another one used by 150,000 devices. By analyzing the facets it's easy to get a picture of systemic issues that plague both hardware manufacturers as well as ISPs/ hosting providers. »
Via https://twitter.com/Keltounet/status/567974628024582144- https://blog.shodan.io/duplicate-ssh-keys-everywhere/
-
Ariège : l'incendie d'un scooter provoque une gigantesque coupure d'Internet | Big Browser
Après les gros animaux qui se font un duel avec les poteaux (aux USA principalement), la pelleteuse, la débroussailleuse contre un poteau (c'est du vécu), la mamie arménienne, le bateau egyptien, la voiture, le feu d'artifice belge, ... voici venu le scooter en feu \o/18/02/2015 10:12:06 - permalink -
Via https://twitter.com/bortzmeyer/status/567791059208765440- http://bigbrowser.blog.lemonde.fr/2015/02/17/ariege-lincendie-dun-scooter-provoque-une-gigantesque-coupure-dinternet/
-
Instrumentaliser la terreur pour contrôler les communications chiffrées : une dérive dangereuse et anti-démocratique | La Quadrature du Net
« Les attentats de janvier à Paris ont déclenché une vague de discours sécuritaires et de dangereux projets législatifs s'annoncent bien au-delà des frontières françaises. Un contrôle des communications en ligne, de la surveillance, des attaques contre l'expression anonyme et le chiffrement sont déjà à l'ordre du jour, sous prétexte de combattre un ennemi invisible dans une guerre perpétuelle.17/02/2015 15:19:12 - permalink -
[...]
Aujourd'hui, le débat public hystérisé alimenté par la peur est instrumentalisé afin de justifier l'adoption hâtive de nouvelles lois sécuritaires. Dans les semaines à venir, MM. Valls et Cazeneuve proposeront une nouvelle loi sur le renseignement. Dans le contexte actuel, il est probable que ce nouveau texte apportera son propre lot de nouvelles mesures de surveillance, de pouvoir renforcé pour l'exécutif et la police, et de réduction constante du rôle du judiciaire en tant que gardienne-fou des droits fondamentaux. Tout porte à croire qu'Internet deviendra le bouc émissaire de ces atteintes à nos libertés.
Cette instrumentalisation de la terreur pour attaquer les libertés fondamentales ne concerne cantonne pas que à la France, elle est une spirale qui entraîne l'ensemble des citoyens européens.
[...]
Un tel sabotage gouvernemental de nos outils quotidiens prouve qu'il n'y a pas de technologie digne de confiance pour la protection de nos données et communications qui ne soit pas du logiciel libre. Le logiciel libre appartient à tous, c'est un bien commun sur lequel nous avons tous, par l'intermédiaire de la publication de son code source, de sa « recette », une capacité collective de compréhension, de participation et de contrôle. Il est beaucoup plus difficile d'inclure des fonctionnalités malveillantes de surveillance dans un logiciel libre si suffisamment d'yeux et de cerveaux vigilants y prêtent attention.
[...]
En outre, c'est une façon de construire des modèles de sécurité résilients permettant à nos sociétés de mieux résister à des tentatives de contrôle totalitaire. Des politiques industrielles intelligentes pourraient favoriser le développement de logiciel et matériel libres (par entre autres des incitations fiscales, la commande publique, l'éducation supérieure) comme un objectif stratégique pour un futur technologique permettant des sociétés libres et justes.
[...]
Lorsque David Cameron pose la question rhétorique : « Souhaitons-nous autoriser des moyens de communication inter-personnelles que nous (le gouvernement) ne pouvons pas lire ? », la réponse collective doit être « Oui, absolument, et les gouvernements doivent protéger ce droit ! ». La possibilité d'écrire et de communiquer sans être surveillé est une condition essentielle pour la liberté d'expression et la démocratie. Les communications privées sécurisées sont l'un des rares outils dont disposent les citoyens du monde entier pour s'organiser contre l'oppression et la tyrannie. (NDLR : cf article 2 de la Déclaration des Droits de l'Homme et du Citoyen de 1789 ]
[...]
Les enquêteurs qui travaillent sur des crimes graves disposent d'une multitude de moyens d'accéder au contenu des communications d'un individu, à travers une surveillance ciblée qui peut et doit être contrôlée démocratiquement. Plutôt que d'affaiblir la cryptographie de tous les citoyens du monde, ils peuvent par exemple intercepter en clair les entrées et sorties des communications chiffrées d'un individu par le biais d'un mouchard placé sur sa machine, de caméras ou de micros espions, de l'infiltration des réseaux, etc. Dans la plupart des cas, ce sont bien ces « bons vieux » moyens d'enquête ciblée, qui doivent obligatoirement être soumis au contrôle d'un juge judiciaire indépendant, qui permettent une prévention efficace des crimes et du terrorisme. Les autres techniques, basées sur la surveillance de masse et la corruption de la technologie elle-même sont inefficaces pour cela. En permettant un espionnage économique et politique de grande envergure, elles sont un redoutable outil de contrôle social, menant inévitablement à des abus. Cette doctrine est incompatible avec la démocratie.
[...]
Si les libertés fondamentales, y compris le droit aux communications privées et à l'expression anonyme, ne sont pas pleinement protégés par ceux qui prétendent combattre les criminels qui cherchent à détruire nos sociétés, nous obtiendrons à coup sûr le pire des deux mondes : la peur et le contrôle autoritaire.
En tant que citoyens, nous devons résister collectivement à cette instrumentalisation de la terreur par ceux qui veulent restreindre nos libertés et contrôler les populations, avec l'illusion qu'ils seront ainsi maintenus au pouvoir. Pour ce faire, nous devons investir nos énergies dans la diffusion, le développement et l'amélioration des technologies basées sur le logiciel libre, les communications décentralisées et le chiffrement de bout-en-bout. En parallèle, nous devons créer une dynamique politique pour imposer une évaluation en profondeur des pratiques de surveillance et reprendre le contrôle des institutions de renseignement lorsqu'elles sont hors de contrôle, et mettre en place des politiques qui protégeront efficacement et durablement nos libertés en ligne et hors ligne. »- http://www.laquadrature.net/fr/instrumentaliser-la-terreur-pour-controler-les-communications-chiffrees-une-derive-dangereuse-et-ant
-
Sortie du noyau Linux 3.19 - LinuxFr.org
« La A20-OLinuXino-Lime2 est une carte de développement en matériel libre produit par OLimex. Elle dispose d’un système monopuce Allwinner A20 (double‐cœur Cortex A7 cadencé à 1 GHz, un processeur Mali-400), 1 Gio de mémoire vive DDR3, un connecteur HDMI Full HD 1080p, un connecteur LCD (4,3″, 7,0″ et 10,1″), de l’USB 2.0, un contrôleur Ethernet Gigabit, un lecteur de carte microSD, un connecteur SATA et permet de pouvoir connecter jusqu’à 160 GPIO. Ces deux cartes sont désormais prises en charge par le noyau Linux mainline.17/02/2015 10:55:54 - permalink -
[...]
Le problème lié à l’année 2038 est toujours là. Les fonctions internes do_settimeofday(), timekeeping_inject_sleeptime(), et mktime() ont maintenant des remplaçants sûrs pour le bogue de l’année 2038. Dans chaque cas, la nouvelle version ajoute « 64 » au nom de la fonction, et passe au type time64_t ou timespec64 pour représenter le temps. Maintenant, il est possible de rendre obsolètes les anciennes versions et la conversion du code peut commencer.
[...]
Le nouveau pilote ipvlan permet la création de réseaux virtuels pour l’interconnexion de conteneurs. Il est conçu pour fonctionner avec les espaces de noms en réseau [NDLR : netns]. Ipvlan est un peu comme le pilote macvlan existant, mais il fait son multiplexage à un niveau plus haut dans la pile.
Lors de la création de plusieurs espaces de nom, conteneur ou invité (sous-hôte) sur un hôte, plusieurs modes de connexion au réseau sont généralement disponibles (hôte seulement, NAT, pont réseau).
Dans le cas d'un pont réseau (l'équivalent d'un switch), l'hôte possède une interface physique (généralement appelée maître), éventuellement une interface représentant le pont, et une interface reliée (esclave) pour chaque sous-hôte.
Le plus généralement, on utilise le pilote bridge (man brctl). Il est cependant utile de limiter les interactions de chaque sous-hôte. Là où macvlan répartit les paquets en fonction de l'adresse mac (Niveau 2), ipvlan peut le faire en fonction de l'adresse IP (Niveau 3). [NDLR : ipvlan permet d'avoir deux interfaces, la master sur l'hôte (dans le netns) et la slave dans le conteneur au lieu de trois interfaces (2 sur l'hôte, 1 dans le conteneur càd l'interface "physique" de sortie et 2 veth).]- http://linuxfr.org/news/sortie-du-noyau-linux-3-19
-
Cinquante nuances de fouet. |
« [...] le parlement européen avait proposé une résolution de soutien à [NDLR : Raïf] Badawi [NDLR : blogueur saoudien]. J’ai été vérifier parce que je le trouvais quand même vachement bien informé pour un animal dont 78% du temps disponible est consacré à essayer d’attraper sa propre queue, mais c’était vrai dites donc, le parlement européen condamnait sa flagellation, y voyant « un acte de cruauté révoltant », et demandent aux autorités saoudiennes de le libérer immédiatement et sans condition.17/02/2015 10:41:17 - permalink -
Même qu’ils disaient que le cas de Raïf Badawi était « symptomatique des atteintes à la liberté d’expression et d’opposition pacifique dans le pays, et, plus largement, de la doctrine d’intolérance et d’interprétation extrémiste du droit islamique prônée par le royaume ». [Communiqué du Parlement]
[...]
et je vois que la proposition a bien été adoptée la semaine dernière. Mais adoptée par 460 voix contre 153 et 29 abstentions.
[...]
J’ai regardé s’il y avait des Français dans la liste des députés ayant voté contre.
Il y avait des Français.
Il y avait :
Brice Hortefeux, Nadine Morano, Jérôme Lavrilleux, Philippe Juvin, Alain Cadec, Michel Dantin, Angélique Delahaye, Alain Lamassoure, Françoise Grossetête , Elisabeth Morin-Chartier, Renaud Muselier, Maurice Ponga, Franck Proust, Anne Sander et Tokia Saifi.
Je me suis dit que pas de panique, ces gens-là avaient dû expliquer sur leur site officiel, leur blog, leur facebook, leur twitter le pourquoi du comment, et que j’allais pouvoir l’expliquer à mon chat.
J’ai pas trouvé.
Je re-cherché.
J’ai re-pas trouvé.
[...]
Alors du coup, chers députés européens, chers quinze députés, voilà pourquoi je vous écris.
Si vous aviez cinq minutes pour nous expliquer pourquoi vous avez voté contre cette résolution, pourquoi vous que nous avons élu, vous qui nous représentez, vous qui portez notre voix, vous qui nous incarnez, avez choisi de refuser de dire non à la barbarie et la torture, je vous serais reconnaissante. Expliquez-nous de quel droit vous vous êtes permis de penser que nous ne voulions pas condamner l’ignominie, soyez sympa. »
Via http://news.korben.info/cinquante-nuances-de-fouet-klaire-fr- http://www.klaire.fr/2015/02/16/cinquante-nuances-de-fouet/
-
Louis Pouzin: "Internet est bâti sur un marécage" - L'Express L'Expansion
Bonne analyse politique (au sens noble), à lire. Le reste (vision de l'Europe, refonte d'IP, le mythe de "pas de sécurité au début du net car on était entre hippies", contrôle total des USA sur Internet) est à jeter, comme d'habitude avec grand-papa Louis.16/02/2015 15:48:46 - permalink -
« Louis Pouzin [...] cet ingénieur français, polytechnicien, est à l'origine, dans les années 1970, du premier réseau -appelé "Cyclades"- permettant de communiquer des informations sous la forme de paquets. L'octogénaire travaille toujours à la refonte de la Toile.
[...]
Les Etats-Unis ont été pris d'une paranoïa sécuritaire après les événements du 11-Septembre, suscitant l'émergence d'une industrialisation de la surveillance de masse sous l'ère de George W. Bush. Barack Obama n'a fait que légaliser, a posteriori, ce qu'a mis sur pied son prédécesseur sans l'intervention des juges. Tous les services de renseignement de chaque pays échangent des informations depuis bien longtemps. Ils peuvent aussi en garder certaines pour eux, ou encore en transmettre des fausses.
Ce sont de vieux procédés dont l'origine remonte à la Seconde Guerre mondiale. Mais cela finit par être aberrant dès lors que les enregistrements deviennent systématiques et massifs, prélude à une société totalitaire. Quand un gouvernement est capable de tout savoir, plus personne n'ose rien dire. Déjà, au sein même de l'agence de sécurité américaine, la NSA, des personnes utilisaient ce pouvoir pour surveiller leurs conjoints, leurs amis, leurs enfants, leurs collègues.
L'étape suivante consiste à faire commerce de ces informations. Bien évidemment, les dirigeants vont renforcer les contrôles pour éviter ce genre de dérive, mais, dès que 2 000 à 5 000 personnes ont accès à ces éléments, les fuites se multiplient et il devient compliqué de tout maîtriser. A la fin, tout le monde a peur de tout le monde, et la légitimité des gouvernants s'effondre. Car les élus sont potentiellement menacés. On le sait bien, tout politicien a des choses répréhensibles à cacher, et chacun d'eux devra obéir à des consignes, sous peine de voir ces informations déplaisantes divulguées au grand public. En suivant cette logique implacable, on aboutit à la fin de la démocratie et à la naissance de la Stasi.
[...]
La NSA sait aussi ce qui se passe en France et peut échanger avec les autorités hexagonales les informations collectées. Pour rester dans la légalité, les services de renseignement n'écoutent pas la population de leur pays. Afin de contourner ce problème, ils s'échangent les données amassées par des services étrangers sur leurs propres sols. La France y participe. Bien entendu, elle ne peut aller aussi loin que la NSA, car elle ne dispose pas des mêmes ressources financières.
[...]
Que ce soit les carnages survenus aux Etats- Unis ou la tuerie de Charlie Hebdo en France, dans tous les cas les services de renseignement disposaient des éléments nécessaires pour agir. Les personnes étaient déjà sous surveillance et cela n'a rien empêché du tout. Les suspects se comptent par milliers dans un pays, il est donc impossible de tous les suivre à la trace, et un minimum d'entre eux finit par passer au travers des mailles du filet. Ensuite, les actes de ces "martyrs" sont médiatisés pour inciter d'autres à en faire autant.
[...]
Pour éviter les dérives, il faut limiter la surveillance aux domaines strictement nécessaires. Le téléphone a toujours été mis sur écoute, le courrier ouvert, mais, chaque fois, sous l'autorité d'un juge, dans des conditions définies et bien précises. Sans cette digue, tous les abus sont permis.
[...]
Dans ce cadre aussi, le juge disparaît alors même qu'il pose des limites et que ses décisions sont connues de tous, soumises au jugement des citoyens. Bloquer la diffusion de contenus est donc un leurre. Nul ne peut empêcher la circulation de clefs USB chargées de vidéos.
On peut limiter la propagation d'informations gênantes, restreindre leur volume, punir les contrevenants, mais il est impossible de bannir totalement leur diffusion. Les moyens existants sont bien trop puissants. Toute cette gesticulation politique ne vise qu'à rassurer le peuple. Si on protège les écoles, les synagogues, c'est pour cette même raison, mais les policiers en faction ne peuvent rien empêcher.
[...]
Les régimes démocratiques veulent surveiller Internet pour des questions de sécurité et les dictatures pour maîtriser leur peuple. Cette tentation totalitaire est-elle inéluctable?
Au bout du compte, il s'agit toujours de contrôler la population. Seul le langage politique change. En Chine ou dans nombre de pays arabes, certains interdits peuvent être acceptés par la population, car elle a été intoxiquée par un discours politique ou religieux. Dans le cas des démocraties, on cherchera davantage à mettre en avant la violation de règles ou la mise en évidence de liens avec des organisations sulfureuses pour rendre un internaute suspect.
[...]
L'état de développement des technologies permet d'aller très loin et l'escalade dans la surveillance entre les pays existe, comme ce fut le cas dans la course aux armements. Il y a toujours une période durant laquelle une nation possède une avance technologique, avant que les autres ne la rattrapent. Si on veut en limiter l'impact, les citoyens doivent rendre leurs communications illisibles aux agences de renseignements grâce au chiffrement.
[...]
C'est un système de colonisation bien connu depuis le XVIIIe siècle : on utilise les ressources du pays occupé pour les lui revendre après traitement.
Les acteurs de cette colonisation, ce sont Google, Facebook, Microsoft, Apple?
Absolument. Il s'agit d'une colonisation informationnelle. Aujour d'hui, la richesse ne provient plus de l'industrie textile, des machines- outils ou même de l'exploitation du pétrole, mais bien de l'information, un domaine dans lequel ces acteurs détiennent un avantage déterminant. »
Via https://twitter.com/bortzmeyer/status/567328037713502208- http://lexpansion.lexpress.fr/high-tech/louis-pouzin-internet-est-bati-sur-un-marecage_1650342.html
-
17 mensonges que nous devons arrêter de dire aux filles [et aux garçons !] à propos du sexe - Peuvent-ils souffrir ?
Rappels de base pour la plupart mais ça ne fait jamais de mal de radoter.16/02/2015 13:27:19 - permalink -
Via http://sebsauvage.net/links/?jAVFRg- https://peuventilssouffrir.wordpress.com/2014/05/04/17-mensonges-que-nous-devons-arreter-de-dire-aux-filles-a-propos-du-sexe/
-
Découvrez la différence entre une diplomatie de gauche et une diplomatie de droite : Reflets
Un peu dommage l'anti-gauche primaire... l'UMP/RPR n'a pas fait mieux en son temps, hein... Ni le PS avant lui. Mais les exemples cités valent la peine d'être mémorisés/rabâchés.16/02/2015 12:14:16 - permalink -
« Le changement c’est maintenant, disait François Hollande. On a vu. La finance sans visage, son ennemie, qui est devenue son amie au moment où il a été élu. On a vu… Les milliards de cadeaux offerts au Medef, sur un plateau. Avec un résultat sans égal. Les patrons n’ont pas respecté leur part de l’accord. On a vu… La Loi Macron qui va finir de dépecer les restes du code du Travail et qui voulait même, grâce aux bonnes idées de Jean-Jacques Urvoas, offrir aux entreprises un moyen de mettre fin au journalisme d’investigation. On a vu… Les petits arrangements du pouvoir qui ont perduré, les planques aménagées avec salaire confortable pour les amis, afin de patienter jusqu’à la prochaine élection. On a vu… L’impunité qui se poursuit. Jack Lang et sa femme qui déjeunent quasiment aux frais de la princesse avec leurs 1000 amis dans le restaurant sur le toit de l’Institut du Monde Arabe que l’ancien ministre de la culture dirige. On a vu… Claudie Haigneré, ancienne astronaute, recasée par la droite et maintenue par la gauche à la tête d’un établissement public regroupant la Cité des sciences et de l’industrie de la Villette et le Palais de la découverte. Avec un salaire et un budget de fonctionnement que lui envieraient tous les patrons d’établissements publics. (Voir pour ces deux dernières affaires le Canard Enchaîne du mercredi 11 février 2015). On a vu. Le changement, ce n’est ni hier, ni maintenant, ni demain.
Dans le domaine de la diplomatie, c’était déjà marquant durant les 100 premiers jours de la présidence Hollande. Le nouveau président avait en effet reçu le roi du Maroc (le mouvement du 20 février appréciera), le roi de Bahreïn (Najib Rajab appréciera), le premier ministre du Qatar, le fils du roi d’Arabie saoudite, le roi de Jordanie et le prince héritier d’Abu Dhabi. Tous pays connus pour leur souci du respect des Droits de l’Homme. Et pour leur goût prononcé pour les technologies de surveillance globale.
Alors qu’il y a quelques jours la FIDH s’inquiétait de la lenteur de la procédure contre Amesys et sa vente d’un système de surveillance globale à la Libye, un message très clair vient d’être envoyé par la présidence française au pôle spécialisé dans les crimes contre l’humanité, crimes et délits de guerre au sein du TGI de Paris. Première salve : la vente accélérée et rocambolesque d’avions Rafale à l’Egypte du maréchal Abdel Fattah al-Sissi. Un vrai démocrate ce al-Sissi. Arrivé à la faveur d’un putsch qui arrangeait les occidentaux (il chassait les méchants islamistes), il s’est illustré en emprisonnant des journalistes, en laissant des massacres être perpétrés par les forces de sécurité. Deuxième salve : Bernard Cazeneuve, en visite au Maroc, vient d’annoncer qu’Abdellatif Hammouchi, patron du contre-espionnage marocain, déjà Chevalier de l’ordre de la Légion d’honneur depuis 2011, allait recevoir les insignes d’Officier.
Que peut-on faire de mieux, pour soutenir les peuples en lutte contre des Etats policiers qui se distinguent par leur usage de la torture contre les opposants politiques, que de leur vendre des armes et de leur distribuer des breloques ? Que peut-on faire de mieux pour soutenir la justice française qui tente d’auditionner Abdellatif Hammouchi dans le cadre de deux plaintes différentes pour actes de torture et de complicité de tels actes, que de lui décerner les insignes d’officier de la légion d’honneur ? »- http://reflets.info/decouvrez-la-difference-entre-une-diplomatie-de-gauche-et-une-diplomatie-de-droite/
-
France Cyber Security : une idée française de la sécurité française... : Reflets
De bons points parmi du gras/radotage Reflets habituel.16/02/2015 12:08:07 - permalink -
« C’est beau comme… Comme de l’auto-certification. Comment se faire un peu de pub quand on est un groupe de sociétés françaises spécialisées dans la sécurité informatique ? Simple. Créer un énième label et certifier quelques produits. Petit plus ? Embarquer dans l’aventure des organismes d’Etat. L’arrivée dans le paysage de « France Cyber Security » (évoqué ici par ZDNet) n’est donc pas une surprise. Elle suit le précédent « label » qui ne marchait pas, Hexatrust (dans lequel on trouvait nos amis de Qosmos). Dans tous les cas, bien décorer le site Web avec de la peinture bleue, blanche et rouge, imaginer un logo qui ressemble à s’y méprendre à un écusson de force de police ou de l’armée, et se présenter comme une alternative à la méchante NSA des Etats-Unis. De la sécurité française, façon Super Dupont qui permet de faire la nique aux espions américains. Sauf que tout cela ne suffit pas à faire de la bonne sécurité.
France Cyber Security l’annonce clairement sur son site :
Les principes d’attribution s’appuient principalement sur les critères suivants :
Les produits et services sont fournis et/ou délivrés par une entreprise française
Les produits sont conçus et développés en France.
Les services sont fournis de France et hébergés en France le cas échéant.
La qualité et la performance des produits et services sont attestés par des certifications.
Du vrai produit de sécurité made in France avec du saucisson et de la baguette.
Nos oreilles ont sifflé cette semaine quand, assistant à une conférence de la DGSI visant à sensibiliser les entreprises françaises aux danger numériques, France Cyber Security a été cité comme un lieu intéressant pour choisir des produits permettant d’éviter la curiosité américaine.
Ce label a toutefois du mal à s’auto-certifier lui-même. Le très joli WordPress installé sur le serveur Apache qui héberge ses pages, semble avoir été mis en place sans supervision… d’un expert en sécurité (française ou pas). [...] Il ne s’agit pas d’un simple petit oubli puisque le site offre d’autres informations : il est possible de consulter les fichiers uploadés sur le site [...] Piste de réflexion (cadeau Bonux) le site Hexatrust qui regroupait déjà la fine fleur de la sécurité informatique made in France, présente le même genre de problème. [...]
Moralité ? L’auto-certification ne certifie pas grand chose… »- http://reflets.info/france-cyber-security-une-idee-francaise-de-la-securite-francaise/
-
« Surveiller, tout en se cachant, est la forme la plus haute du pouvoir » - Rue89 - L'Obs
Très bonne analyse, à lire. Le seul point noir est l'approche "le gouvernement pourrait nous sauver s'il le voulait"/"les élites également". Non, juste NON, N-O-N : il ne faut rien laisser à des prétendues élites et il faut se bouger pour obtenir ce que l'on désire. À mettre en lien avec : http://www.nextinpact.com/news/93072-les-deputes-retirent-secret-affaires-loi-macron.htm16/02/2015 11:47:06 - permalink -
« Frank Pasquale, professeur à l’Université du Maryland, vient de publier « The Black box society ». Il décrit comment les algorithmes, protégés par le secret commercial, créent de nouveaux rapports de pouvoir.
[...]
En 2003, il y a eu un premier procès contre Google : celui-ci faisait systématiquement descendre dans ses résultats une entreprise appelée SearchKing, qui était un autre moteur de recherche. Or il était impossible de savoir si Google essayait délibérément de se débarrasser d’un concurrent ou si le site descendait automatiquement dans les résultats parce qu’il était mauvais. On ne pouvait pas savoir parce que les algorithmes de Google, qui régissent ces résultats, sont protégés par le secret commercial.
[...]
Aux Etats-Unis, Latanya Sweeney, professeure de droit à Harvard, s’est aperçue que quand elle faisait une recherche avec son nom dans Google, elle voyait apparaître des publicités automatiques proposées par AdSense titrées « Latanya : arrêtée ? ». Elles proposaient d’accéder à son casier judiciaire (via instantcheckmate.com), suggérant ainsi qu’elle avait déjà été condamnée. Par contre, si elle cherchait « Tanya Sweeney », alors les publicités qui s’affichaient lui proposaient de simples services de localisation, avec des titres neutres comme : « Tanya Sweeney : nous l’avons retrouvée pour vous ». La différence, c’est que Latanya est un prénom que l’on trouve plus souvent chez les Afro-américains, alors que Tanya est plus souvent un prénom « blanc ».
Latanya Sweeney a recherché sur Google les 2300 noms les plus représentés chez les Afro-américains. Elle a découvert que la plupart du temps, les mêmes publicités de instantcheckmate.com s’affichaient, avec le prénom suivi de « arrêtée ? » Ce n’était pas le cas pour les prénoms connotés « blancs ». En réponse, Google et les annonceurs ont affirmé que le processus était entièrement automatisé, et reflétait ce sur quoi les gens cliquaient le plus.
Et ceci est loin d’être un cas isolé : il y a déjà eu des problèmes similaires avec les posts recommandés de Facebook, par exemple.
[...]
Auparavant, le secret commercial s’appliquait aux personnes les plus haut placées dans les entreprises. Aujourd’hui, les entreprises attachent une telle importance à leurs secrets qu’elles l’appliquent jusqu’en bas de la hiérarchie. Aux Etats-Unis, le secret commercial est même utilisé pour forcer les employés de la chaîne de sandwichs Jimmy John’s à signer un contrat de confidentialité sur la composition de leurs sandwichs ! En revanche, les actions des dirigeants restent cachées dans ces boîtes noires – protégées par le secret commercial, le jargon qu’ils emploient et des techniques de verrouillage et de cryptographie.
[...]
Absolument. La capacité de surveiller les moindres faits et gestes des autres, tout en cachant les siens, est la forme la plus haute du pouvoir.
C’est l’histoire platonicienne de l’anneau de Gygès : celui qui est invisible, et qui donc peut voir tout ce que font les autres à leur insu, dispose d’un avantage stratégique énorme. C’est le ressort central d’entreprises comme Google ou Facebook. Elles disent qu’elles doivent leur richesse et leur succès au fait d’avoir les meilleurs analystes de données et les meilleurs algorithmes. Mais ce succès tient moins à des compétences spéciales qu’à une position de pouvoir particulière, qui leur permet de surveiller tout le monde en se soustrayant elles-mêmes aux regards.
[...]
Les entreprises spécialisées dans la réputation, c’est la vision à la première personne. Ma réputation, c’est la façon dont les autres me perçoivent et me connaissent, et les algorithmes de réputation participent à cette interprétation.
Les moteurs de recherche, c’est la façon dont j’essaie de comprendre le monde qui m’entoure.
Et la finance... avec le secteur militaire, c’est ce qui détermine in fine nos marges de manœuvre. Et ils utilisent ces technologies de réputation et de recherche.
[...]
C’est le journaliste américain Clay Shirky qui a exprimé cette idée d’autorité algorithmique, qu’on peut résumer ainsi : avant, la meilleure source faisait autorité. Si je voulais trouver le meilleur article d’info internationale, j’allais voir sur le site du New York Times ou du Guardian, des journaux qui font autorité à cause de leur ancienneté, des prix de journalisme qu’ils ont reçus, etc.
Dans le monde de l’autorité algorithmique, je vais sur Google et je tape « meilleur article d’info internationale ». Google me propose un millier de résultats parmi lesquels il en sélectionne un en tête de liste. Ici, ce n’est plus la source qui crée autorité mais mes précédentes recherches Google. Or je ne sais rien des algorithmes qui choisissent pour moi.
Pour Shirky, c’est une bonne chose. Mais je suis plus critique et j’interroge ce que nous perdons lorsque nous entrons dans le monde de l’autorité des algorithmes. Ce qu’il promet, évidemment, c’est qu’aujourd’hui n’importe qui peut voir son article en tête des résultats de Google News, ce n’est plus réservé à un petit groupe de gens « légitimes » comme ceux du New York Times.
Mais nous ignorons tout des arrangements commerciaux qui existent entre Google et les entreprises de notation et classement. Quels sont leurs buts ? Capter plus de notre attention ? Récolter plus de données ? Nous savons vraiment peu de choses sur cette autorité algorithmique et ce qui l’anime.
[...]
Pour construire un algorithme, vous êtes obligé de donner la priorité à un certain type de signal, parmi tous les signaux que vous recevez.
[...]
Si Google n’était qu’une grosse machine automatique, que l’entreprise mettait en marche sans plus intervenir après, alors cet argument serait recevable. Mais en réalité, il existe de nombreux contre-exemples.
A un moment donné, si l’on tapait « juif » (« jew ») dans le moteur de recherche, on tombait en premier sur un site antisémite et négationniste. Ce n’était pas le cas pour « Israel » ou « Jewish », mais pour « Jew », qui est le terme utilisé par les antisémites : ceux-ci se trouvaient algorithmiquement propulsés vers le haut des résultats. A ce moment-là, Google avait vivement réagi en affichant un message sur leur page de résultat, disant qu’ils ne cautionnaient ni la validité du site ni sa crédibilité.
Cela tient beaucoup aux contraintes que les développeurs acceptent comme légitimes, et à celles qu’ils refusent.
[...]
D’abord il faut arrêter de vénérer ces entreprises, comme si ce qu’elles faisaient était aussi génial et compliqué qu’envoyer un homme sur la Lune ou guérir le cancer. Les gens doivent commencer à comprendre, même grossièrement, comment fonctionne le « big data » : comment les données sont récoltées, nettoyées, utilisées.
Nous avons aujourd’hui un vrai problème culturel : beaucoup, beaucoup de gens, parmi lesquels des politiques, n’ont pas la moindre idée de comment tout ceci fonctionne. Ils voient ça comme quelque chose de magique, et pensent qu’il faut être un génie pour faire ça. J’essaie de calmer un peu ces ardeurs, et de dire que si ces entreprises ont la position dominante qu’elles ont aujourd’hui, c’est surtout parce que ce sont elles qui possèdent le plus de données.
De plus, c’est l’intelligence collective qui aide Google à affiner ses algorithmes. Google, c’est nous tous, c’est toutes nos recherches sur le Web. Même chose pour Instagram. On s’émerveille en disant : « oh, il n’y a que quatorze personnes pour faire tourner Instagram, alors qu’il y en avait 14 000 chez Kodak. Ces quatorze personnes sont incroyablement intelligentes ! » Mais non ! Ces quatorze personnes ne représentent rien, comparées à l’ensemble des photos que nous prenons !
[...]
Oui, je pense qu’on peut dire ça. Aujourd’hui, sont concentrées un nombre considérables de richesse et de données dans les mains d’un tout petit nombre d’entreprises qui maîtrisent des algorithmes clés. On peut donc dire que les algorithmes accroissent les inégalités sociales au lieu de les redresser.
Bien sûr, il existe des contre-exemples : un algorithme pourra estimer qu’on peut accorder du crédit à quelqu’un à qui on n’en aurait jamais donné. Les algorithmes permettront aussi de nouvelles façons d’apprendre, nous feront découvrir des choses que nous n’aurions jamais perçues autrement. C’est une dimension évidemment très importante. Mais nous devons aussi regarder leurs côtés négatifs et comprendre que des régulations et des politiques publiques peuvent répondre aux problèmes que ces algorithmes engendrent. Ce n’est pas un phénomène naturel qui poursuit un processus inéluctable.
[...]
En ce qui concerne la protection de la vie privée, celle-ci doit être appliquée bien plus strictement pour protéger les individus. Le secret commercial, dans bien des cas, n’est que l’appropriation des lois sur la protection de la vie privée par les entreprises. A mon sens, chaque mesure qui étend le secret commercial pour les entreprises doit être compensée par une mesure équivalente dans la protection de la vie privée des individus. Les courtiers en données ne devraient pas pouvoir avoir un dossier sur moi sans que je puisse le consulter, l’annoter, le contester et le faire modifier si besoin.
[...]
Quant à remplacer les systèmes propriétaires par des versions open source... [...] Si je ne faisais qu’envoyer des mails, poster des photos sur Instagram... Mais je fais toutes ces choses en même temps, en plus de ma vie professionnelle et familiale. Je n’ai pas le temps de faire tout ça, tout simplement ! Et si même moi, que ces questions préoccupent suffisamment pour que j’en fasse un livre, je n’ai pas le temps, je doute que beaucoup de gens l’aient. »
Via https://twitter.com/MathildeCarton/status/567247825747341312- http://rue89.nouvelobs.com/2015/02/15/surveiller-les-autres-tout-cachant-est-forme-plus-haute-pouvoir-257575
-
HP Officejet 2620 tout-en-un - HP Store France
Je voulais une imprimante/scanner jet d'encre pour pas cher. Raisons :14/02/2015 21:49:01 - permalink -
- On a toujours un papier à scanner/photocopier pour une entreprise ou une administration ;
- Pas suffisamment pour qu'une imprimante laser soit rentable, àmha ;
- Les magasins de photocopie/impression c'est bien mais :
- Le coût de revient à la page est parfois cher (en incluant le coût du transport pour se rendre au magasin sinon la comparaison est biaisée, àmha) ;
- Je n'ai aucune garantie que la personne qui gère le magasin ne dump pas le contenu de ma clé, volontairement (logiciel installé sur l'ordinateur) ou non (imprimante qui mémorise les X dernières impressions par défaut, par exemple). Le risque se réduit en mettant uniquement le strict minimum (ce qui doit être imprimé) sur la clé mais ne s'évite pas totalement ;
- Quand ce n'est pas en libre service, il arrive que le personnel regarde copieusement le contenu de vos documents. Vous pouvez le faire remarquer mais le mal est déjà fait. On a tous des documents plus sensibles que les autres à scanner/photocopier. Et il n'y a pas toujours de la concurrence dans un périmètre géographique donné. C'est le cas dans la ville/quartier où je suis actuellement ;
- Il faut pouvoir s'y déplacer en dehors des heures de travail.
Dans le passé, j'ai eu une excellente prestation avec la HP Deskjet f2480 All-in-one : prix attractif (69€), toujours en état de fonctionnement 3 ans plus tard, compatible GNU/Linux avec le logiciel libre hplip dont la version packagée dans Squeeze permettait un support out-of-box, elle fait ce qu'on attend d'elle, ...
J'ai donc voulu recommencer avec HP. Le modèle le moins cher (et compatible GNU/Linux, j'y viens) à la vente dans la grande surface du coin est une Officejet 2620 All-in-one pour 56€. Moins chère que la Deskjet f2480 pour plus de fonctionnalités (écran de contrôle, chargeur automatique de documents, fonctionnalité fax), une finition équivalente (on sent bien que ce n'est pas conçu pour durer ad vitam eternam, que c'est fragile) et un support par hplip à partir de la version 3.13.11 (http://hplipopensource.com/hplip-web/models/officejet/officejet_2620_series.html).
Première déception : un câble téléphonique (pour la fonctionnalité fax) et un adaptateur secteur pour un autre type de prise électrique sont fournis mais surtout pas le câble USB type B mâle <-> USB type A mâle nécessaire pour la relier à l'ordinateur ! J'avais un tel câble dans mon stock mais sinon c'est à prendre en compte dans le prix d'achat qui n'est donc plus de 56€ !
Deuxième déception : la page du projet hplip concernant l'Officejet 2620, http://hplipopensource.com/hplip-web/models/officejet/officejet_2620_series.html, n'est pas claire. En la parcourant rapidement, je comprends que ce modèle est supporté depuis Debian 6.0 soit Squeeze. Or, ce n'est pas le cas ... enfin, pas tout à fait. Dans Wheezy, la version packagée d'hplip est la 3.12.6 alors que le support de l'Officejet 2620 arrive avec la version 3.13.11. En revanche, la dernière version d'hplip, disponible en http://hplipopensource.com/hplip-web/downloads.html peut être compilée sous Wheezy et fonctionne. C'est cela que signifie la page présentant l'imprimante sur le site web d'hplip, pas que le support sera out-of-box à partir de Debian 6.0. Erreur de compréhension temporaire : le support sera out-of-box avec Jessie. :)
Avec le driver 3.15 présent actuellement sur le site web d'hplip, impression OK et scanner avec xsane OK. Avec le driver en version 3.12.6 (natif Debian Wheezy), xsane ne voit pas le scanner, CUPS accepte d'installer l'imprimante avec un autre profile.
Quelques notes sur l'installation d'hplip à partir des sources :
- Si vous avez lancé l'installation une première fois avec sudo bash hplip-3.15.2.run, ce qu'il ne faut pas faire (le vrai script d'install parmi la tripotée fournie vous demandera votre mot de passe root au moment venu), supprimez le dossier $PWD/hplip-$VERSION avant de relancer l'installation sinon vous aurez des erreurs « cd: hplip-3.15.2: Permission non accordée [...] chown: impossible de lire le répertoire « ./hplip-3.15.2 »: Permission non accordée [...] chgrp: impossible de lire le répertoire « ./hplip-3.15.2 »: Permission non accordée » et l'installeur décompressera les innombrables fichiers dans le répertoire courant !
- Dans le même ordre d'idées : puisque ce dossier contient aussi le script de désinstallation, il convient de garder tout cela en état au cas où. Je vous conseille donc de cd /opt ou /usr/local avant de lancer bash hplip-$VERSION.run ;)
- L'installation se passe bien en laissant les choix par défaut. J'ai dérogé pour les questions suivantes :
- « Do you want to setup printer in GUI mode? (u=GUI mode*, i=Interactive mode) » où j'ai choisi le mode intéractif au lieu du mode GUI ;
- « Would you like to perform fax header setup (y=yes*, n=no, q=quit) ? » où j'ai choisi no ;
- « Would you like to print a test page (y=yes*, n=no, q=quit) ? » où j'ai choisi no.
- On peut fermer le System Tray Status Service en cliquant droit -> quit et l'empêcher de démarrer à l'ouverture des sessions en allant dans Applications -> Accessoires -> HP Devices Manager -> Configure -> Preferences... -> System Tray Icon et en cochant « Always hide », Messages to show : None et décochant « Check and notify HPLIP updates ». Puis en allant dans Applications -> Outils système -> Préférences -> Applications au démarrage et en décochant « HP System Tray Service ».
- Message marrant sans conséquence pendant l'installation « A package manager 'sudo tail' appears to be running. Please quit the package manager and press enter to continue (i=ignore, r=retry*, f=force, q=quit) : ». Je faisais bien un sudo tail -f /var/log/dpkg.log en parallèle pour avoir de la visibilité sur les tâches lancées par le script. Ce check est défini dans base/utils.py, fonctions check_pkg_mgr() et Is_Process_Running() qui utilisent la variable package_mgrs remplie pour chaque système GNU/Linux connu dans installer/distros.dat. Dans le cas de Debian, package_mgrs vaut « dpkg,apt-get,synaptic,update-manager,adept,aptitude » et donc ps aux | grep dpkg a détecté mon tail. :D
- Installation de 49 packages (sudo grep "2015-02-14" /var/log/dpkg.log | cut -d ' ' -f 3 | grep -w install | wc -l) et tous viennent bien de la distribution stable (sudo grep "2015-02-14" /var/log/dpkg.log | cut -d ' ' -f 3-4 | grep -w install | cut -d ' ' -f2 | xargs apt-cache policy | grep -B1 sid | grep -o \*\*\* | wc -l => 0 versus sudo grep "2015-02-14" /var/log/dpkg.log | cut -d ' ' -f 3-4 | grep -w install | cut -d ' ' -f2 | xargs apt-cache policy | grep -B1 wheezy | grep -o \*\*\* | wc -l => 49). Ces packages sont des libs nécessaires à la compilation comme libusb, libusb-dev, libsane, libs python, ... et des packages optionnels comme avahi-utils.- http://store.hp.com/FranceStore/Merch/Product.aspx?id=D4H21B&opt=BHC&sel=PRN


{kind=link}
{kind=link}